
Some news from ESA regarding the coming launches of Senti...
In this article, ESA gave us some news of the time table for the coming launches of next Sentinel1 and […]
In this article, ESA gave us some news of the time table for the coming launches of next Sentinel1 and […]

=> Claire Pascal, PhD student at CESBIO, under the supervision of Olivier Merlin (CNRS researcher) and Sylvain Ferrant (IRD researcher) […]
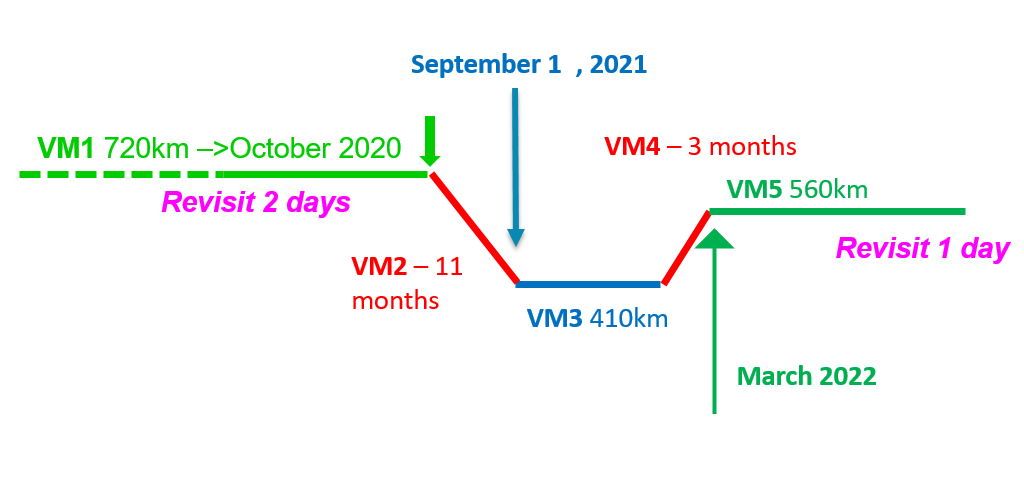
The VENµS satellite was launched in August 2017, with two missions : As a result, VENµS has had different phases […]

Due to Brexit, the ECMWF moved some of its computer infrastructure from Reading (UK) to Bologna (IT), and a 5 […]

Here are some long awaited news about the VENµS VM5 phase. The acquisitions started end of March 2022 with the […]

I found the leak from Nord Stream 2 in the latest Sentinel-1 image (29 Sep 2022). It’s large enough to […]

We are hiring an expert (M/F) in scientific computing to improve the consideration of aerosol type in the MAJA Earth […]
=> You may have noticed an interruption in the availability of level 2 and 3 products on the THEIA portal. […]

=> What can we say, except that the vegetation situation in France has worsened significantly in July 2022 compared to […]

=> The applications of interferometric techniques on radar images are currently developing in many fields. Being able to easily process […]