
Rupture du barrage de Kakhovka : que nous montrent les sa...
La rupture du barrage de Kakhovka au sud de l’Ukraine a eu lieu tôt le matin du 6 juin 2023. […]
La rupture du barrage de Kakhovka au sud de l’Ukraine a eu lieu tôt le matin du 6 juin 2023. […]

Le lidar est magique ! Cette technologie permet de mesurer très précisément l’altitude du sol y compris sous la végétation. […]

People often ask if we can detect artificial snow in satellite images. It’s not so easy except when the surrounding […]

(article publié aussi sur le site du labo-OT au CNES) Pourquoi s’intéresser à l’orientation des cultures agricoles ? Au moins pour […]
International news media reported that the Joshimath city in north India (Uttarakhand) was « sinking » due to a slow landslide. In […]

In early January 2023 the snow cover area in the Alps was lower than the 30 years minimum. The snow […]
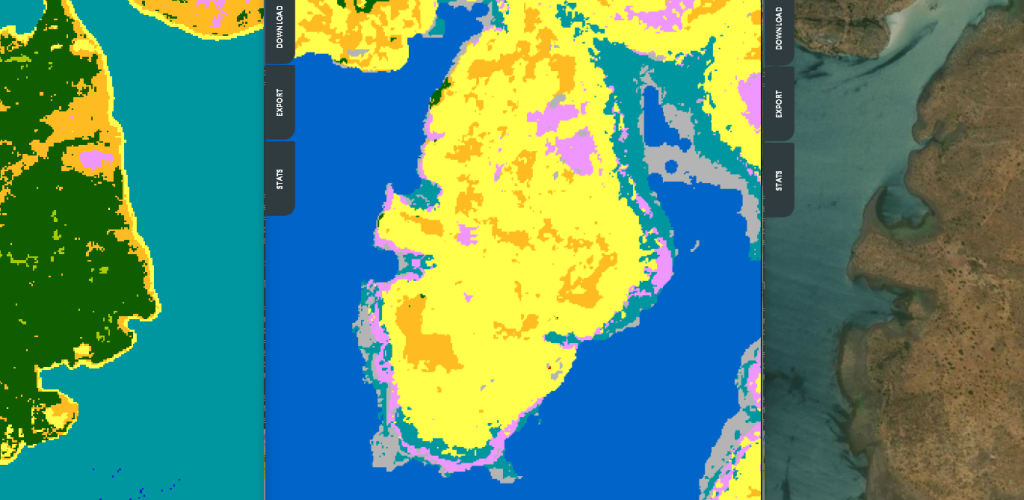
iota2 is the large scale mapping software developed at CESBIO. iota2 takes high resolution satellite image time series (SITS), usually […]

B-22A is the largest iceberg in the Amundsen Sea, Antarctica (50 times Manhattan land area). It broke off from Thwaites […]

J’étais hier dans la maison du parc naturel régional des Pyrénées Catalanes pour discuter des possibilités offertes par la télédétection […]

=> Claire Pascal, PhD student at CESBIO, under the supervision of Olivier Merlin (CNRS researcher) and Sylvain Ferrant (IRD researcher) […]